Un premier essai a été fait avec un réseau de neurones classique. Les PMC (perceptrons multicouches, présentés en section 3) ont été choisis plutôt que les GRBF en raison des caractéristiques du système. En effet l'espace d'entrée du réseau est multidimensionnel, le nombre de dimensions étant égal au nombre de porteuses dans le cas d'un codage binaire à symbole réel, ou au double du nombre de porteuses dans le cas d'un codage binaire à symbole complexe. Les données sont réparties de manière uniforme dans chaque dimension, et donc un réseau GRBF nécessiterait un grand nombre de prototypes pour paver l'espace d'entrée, nombre qui augmenterait exponentiellement avec le nombre de porteuses.
Un PMC réalise une approximation plus globale, et doit pouvoir donc s'accommoder plus facilement d'un nombre de porteuses plus élevé. Trouver le perceptron le plus adapté au problème est une tâche difficile, et qui ne peut être faite qu'expérimentalement. Il ne serait pas intéressant de détailler toutes les simulations qui ont été faites, mais les plus significatives sont présentées dans la suite.
Les simulations ont tout d'abord été faites sur un système OFDM simple : le nombre de porteuses est de 4, la modulation utilisée pour le codage binaire est une MAQ16, et aucun bruit n'est présent sur le canal. Les apprentissages ont été effectués avec un algorithme de descente de gradient (voir en annexe, section 1), qui nécessite de spécifier un coefficient réglant la vitesse de convergence. La valeur de ce coefficient a également été déterminée expérimentalement : une valeur trop faible et la convergence est très lente, une valeur trop importante et l'apprentissage est instable.
Cet apprentissage est effectué à l'aide du gradient total, c'est à dire que lors d'une itération, le gradient est tout d'abord calculé a l'aide de tous les exemples de la base d'apprentissage, puis ensuite les nouveaux poids sont déterminés. Une base de validation est également crée avec le même nombre d'éléments que dans la base d'apprentissage, mais des éléments différents de cette dernière, afin de vérifier que le réseau ne fait pas de surapprentissage. Nous présentons des courbes d'apprentissage, qui montrent l'évolution de la performance des PMC (l'erreur quadratique moyenne) sur les bases d'apprentissage et de validation, au fur et à mesure de l'apprentissage. En abscisse nous avons le numéro de l'itération. Tous les apprentissages ont été réalisés chacun 10 fois. En effet comme l'initialisation des poids du réseau de neurones est faite de manière aléatoire, il faut s'assurer que le profil de l'apprentissage (et principalement l'erreur quadratique moyenne à la fin de l'apprentissage) ne dépend pas de l'initialisation.
Bien que la théorie ait déterminé qu'un PMC avec une seule couche cachée est un approximateur universel et donc pourrait convenir à cette tâche, nous avons principalement testé des PMC à deux couches cachées. En effet en pratique ces perceptrons sont plus efficaces dans de nombreux cas, c'est à dire qu'ils peuvent réaliser des fonctions plus complexes avec moins de paramètres. Par contre l'apprentissage de ces réseaux est généralement plus difficile.
Différentes architectures de PMC ont été employées, en augmentant progressivement le nombre de neurones dans la couche cachée, puis en ajoutant une seconde couche cachée. Des bases de différentes tailles ont également été utilisées. Cependant le temps prohibitif d'apprentissage (jusqu'à 70 heures comme on le verra dans la suite, qu'il faut encore multiplier par 10 car chaque architecture est testée plusieurs fois) ne nous permet pas une étude extrêmement poussée en faisant varier finement tous les paramètres. Nous nous sommes donc limités à quelques bases d'apprentissage et quelques architectures de PMC. Pour simplifier les notations nous noterons 'perceptron-n' un PMC à une couche cachée avec n neurones, et 'perceptron-n-m' un PMC à deux couches cachées constituées respectivement de n et m neurones.
Le critère d'arrêt de l'apprentissage est ici le nombre d'itérations[8], que l'on a limité à 2000. La figure 3.12 montre la courbe d'apprentissage d'un perceptron-10 sur une base de 512 symboles OFDM. On ne peut pas véritablement parler de convergence de l'algorithme car l'erreur quadratique moyenne du réseau continue de décroître au bout de 2000 itérations. Des mesures complémentaires avec un nombre d'itérations bien supérieur seront présentées dans la section suivante.
Figure 3.12. Apprentissage d'un perceptron-10 dans un système OFDM à 4 porteuses avec un amplificateur SSPA, une modulation MAQ16, un recul de 0 dB et avec une base de 512 éléments
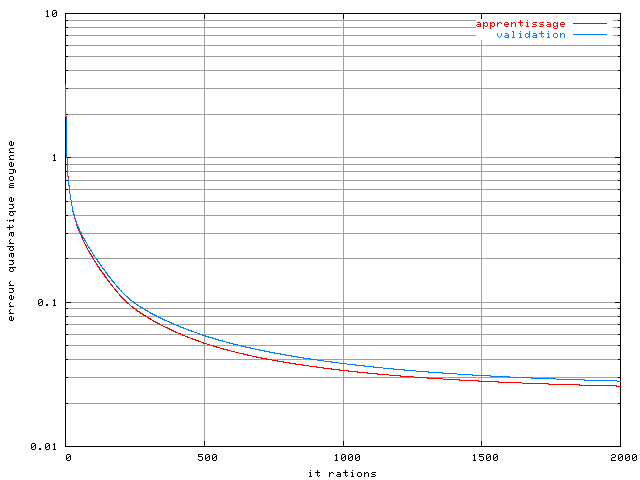
Le même phénomène a été constaté avec des perceptrons ayant un nombre de neurones supérieurs sur la première couche, ainsi qu'avec des PMC à deux couches cachées, comme on le montre figure 3.13 dans le cas d'un perceptron-10-10 :
Figure 3.13. Apprentissage d'un perceptron 10-10 dans un système OFDM à 4 porteuses avec un amplificateur SSPA, une modulation MAQ16, un recul de 0 dB et avec une base de 512 éléments
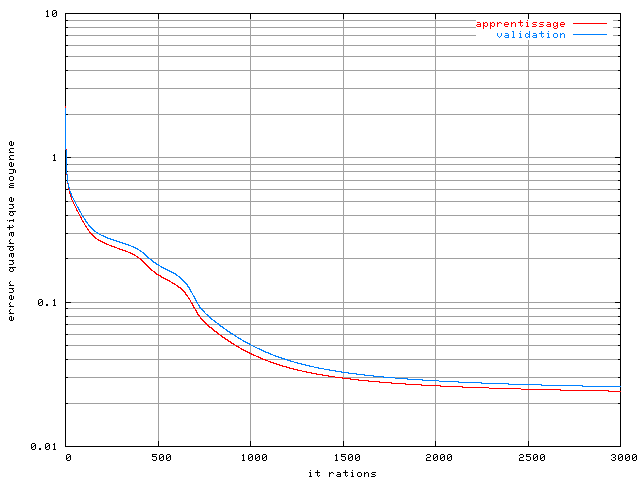
La convergence est plus lente, à cause de l'ajout d'une couche cachée. C'est pour cette raison que le nombre d'itérations avant l'arrêt de l'algorithme d'apprentissage a été augmenté à 3000. On constate une infime diminution de l'erreur quadratique moyenne par rapport au perceptron-10, mais là encore la pente des courbes de performance est négative à la fin de l'apprentissage. Ce phénomène a été constaté sur tous les PMC que nous avons testé.
Les deux courbes d'apprentissage présentées figures 3.12 et 3.13 laissent à penser qu'on devrait pouvoir obtenir une meilleure performance du réseau en augmentant le nombre d'itérations. Un essai a été fait sur un perceptron-30-25, sur une base de 2048 exemples, en portant le nombre d'itérations à 50000 :
Figure 3.14. Apprentissage d'un perceptron-30-25 dans un système OFDM à 4 porteuses avec un amplificateur SSPA, une modulation MAQ16, un recul de 0 dB, une base de 2048 éléments et un plus grand nombre d'itérations
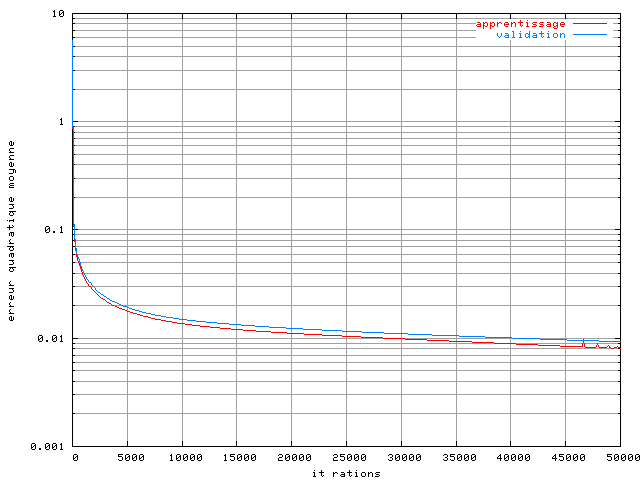
Sur cet essai l'erreur quadratique moyenne après 50000
itérations est de 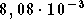 sur la base d'apprentissage et
sur la base d'apprentissage et 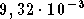 sur la base de validation. La
performance est
bien meilleure qu'avec seulement 2000 itérations, et la pente de la
courbe laisse à penser qu'elle serait encore meilleure si l'on
augmentait encore le nombre d'itérations.
sur la base de validation. La
performance est
bien meilleure qu'avec seulement 2000 itérations, et la pente de la
courbe laisse à penser qu'elle serait encore meilleure si l'on
augmentait encore le nombre d'itérations.
Une comparaison des architectures avec un apprentissage de 50000 itérations serait intéressante, mais n'a pas été faite pour deux raisons : tout d'abord le temps de calcul est plutôt élevé, plus de 24 heures par apprentissage; comme il est nécessaire de faire plusieurs apprentissages sur chaque architecture afin de vérifier l'indépendance du résultat vis à vis de l'initialisation, chaque architecture de PMC demande environ une semaine de calcul. La seconde raison est que rien n'indique que 50000 itérations est en fait suffisant, il est possible que l'erreur quadratique moyenne se réduise encore d'un facteur non négligeable si l'ont continue la descente de gradient. Il est donc sans doute plus utile de travailler sur l'algorithme de convergence lui-même.
Dans une descente de gradient le coefficient qui est utilisé pour la mise à jour des paramètres est déterminant pour la rapidité de convergence et la stabilité de l'algorithme. Dans ces expériences, nous avons déterminé qu'un facteur 0,25 était le plus grand possible sans nuire à la stabilité de l'apprentissage. Il est toutefois possible que durant certaines phases de l'apprentissage, un coefficient plus important puisse permettre d'accélérer la convergence. Nous avons donc fait un apprentissage avec une descente de gradient adaptative (voir en annexe à la fin de la section 1 sur la descente de gradient). Voici la courbe d'apprentissage d'un perceptron 30-25 avec l'algorithme adaptatif :
Figure 3.15. Apprentissage adaptatif d'un perceptron-30-25 dans un système OFDM à 4 porteuses avec un amplificateur SSPA, une modulation MAQ16, un recul de 0 dB et une base de 2048 éléments
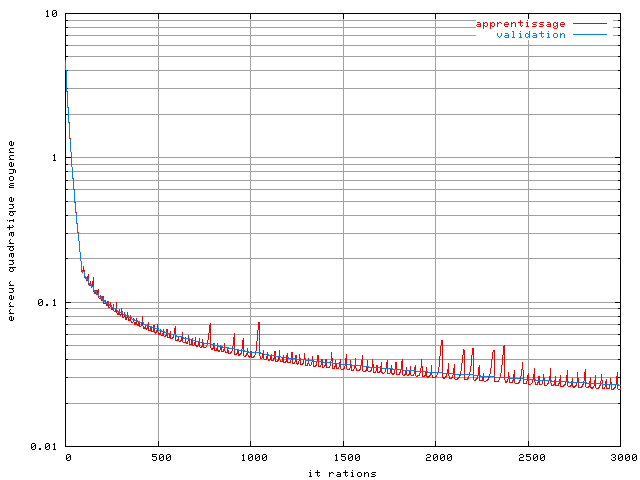
On ne remarque pas d'amélioration de l'apprentissage avec
un algorithme adaptatif, l'erreur quadratique moyenne à
l'itération 3000 étant de 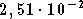 sur la base
d'apprentissage et
sur la base
d'apprentissage et 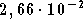 sur la base de validation. Une autre solution est de choisir un
algorithme d'optimisation d'ordre 2, comme
Levenberg
Marquardt (voir en annexe la section 2) qui est couramment utilisé avec
des réseaux de neurones. Les algorithmes d'ordre 2 demandent
généralement moins
d'itérations, mais chaque itération demande beaucoup plus de
puissance de calcul et de mémoire, et ces demandes augmentent très vite
avec le nombre de paramètres du système. L'apprentissage suivant, de
200 itérations sur un perceptron-30-25 sur une base de 2048 éléments a
demandé plus de 70 heures de calcul et près de 800Mo de mémoire :
sur la base de validation. Une autre solution est de choisir un
algorithme d'optimisation d'ordre 2, comme
Levenberg
Marquardt (voir en annexe la section 2) qui est couramment utilisé avec
des réseaux de neurones. Les algorithmes d'ordre 2 demandent
généralement moins
d'itérations, mais chaque itération demande beaucoup plus de
puissance de calcul et de mémoire, et ces demandes augmentent très vite
avec le nombre de paramètres du système. L'apprentissage suivant, de
200 itérations sur un perceptron-30-25 sur une base de 2048 éléments a
demandé plus de 70 heures de calcul et près de 800Mo de mémoire :
Figure 3.16. Apprentissage d'un perceptron-30-25 dans un système OFDM à 4 porteuses avec un amplificateur SSPA, une modulation MAQ16, un recul de 0 dB, une base de 2048 éléments et un algorithme de Levenberg Marquardt
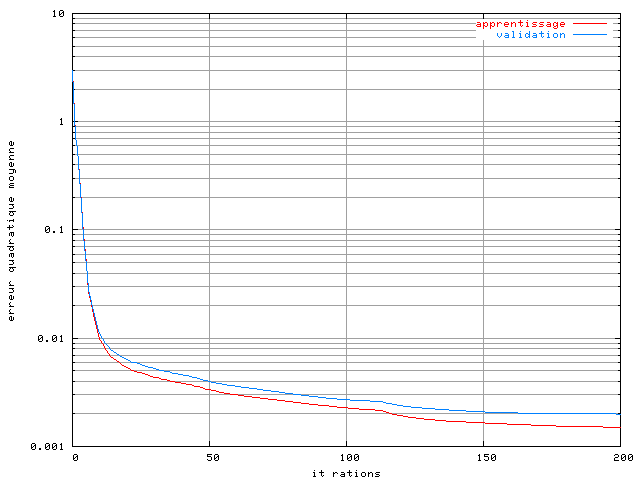
On remarque une amélioration, les performances à l'itération
200 étant de 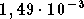 sur la base d'apprentissage et de
sur la base d'apprentissage et de 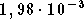 sur la base de validation. Cependant ici encore la pente des courbes de
performance est négative à la fin de l'apprentissage. Il n'a pas
été possible de tester toutes les architectures pour des raisons de
temps de calcul et surtout de mémoire disponible, mais il ces résultats
sont probablement transposables aux autres architectures de PMC.
sur la base de validation. Cependant ici encore la pente des courbes de
performance est négative à la fin de l'apprentissage. Il n'a pas
été possible de tester toutes les architectures pour des raisons de
temps de calcul et surtout de mémoire disponible, mais il ces résultats
sont probablement transposables aux autres architectures de PMC.
Pour évaluer les performances réelles du correcteur, il a ensuite été simulé dans un système OFDM (comprenant l'émetteur avec amplificateur SSPA, le canal gaussien, et le récepteur) avec différentes architectures de PMC. Quelques résultats sont présentés figure 3.17. La courbe 'ref' correspond au système de référence, sans correcteur mais avec la non-linéarité. Ensuite les correcteurs présentés utilisent un perceptron-10 ('p1'), un perceptron-30-25 après 2000 itérations d'apprentissage ('p2'), un perceptron-30-25 après 50000 itérations ('p3'), un perceptron-65-45 ('p4') et enfin un perceptron-30-25 avec un apprentissage par l'algorithme de Levenberg Marquardt ('p5').
Figure 3.17. Taux d'erreur binaire d'un système OFDM à 4 porteuses avec une modulation MAQ16, un amplificateur SSPA, un recul de 0 dB et un correcteur à PMC (apprentissage sans bruit)
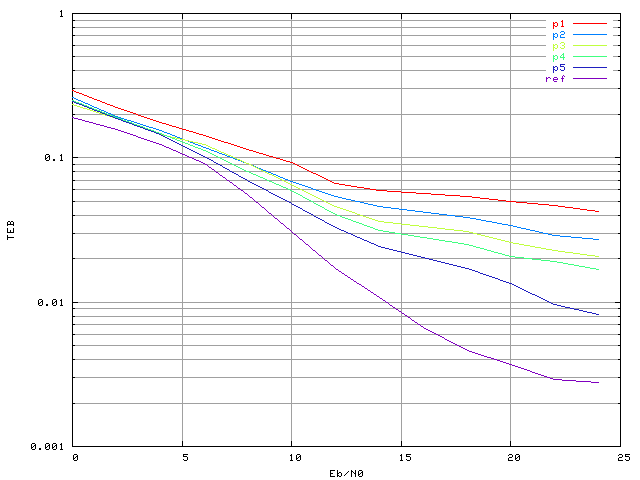
On constate qu'aucun perceptron ne permet de réduire le taux d'erreur par rapport à un système sans correcteur. La même chose a été constatée si l'on fait apprendre les PMC avec une base bruitée (figure 3.18). La base d'apprentissage a été créée avec un rapport signal sur bruit de 13 dB. Une discussion sur le choix de ce rapport signal sur bruit aura lieu dans la section suivante.
Figure 3.18. Taux d'erreur binaire d'un système OFDM à 4 porteuses avec une modulation MAQ16, un amplificateur SSPA, un recul de 0 dB et un correcteur à PMC (apprentissage avec bruit : Eb/N0=13 dB).
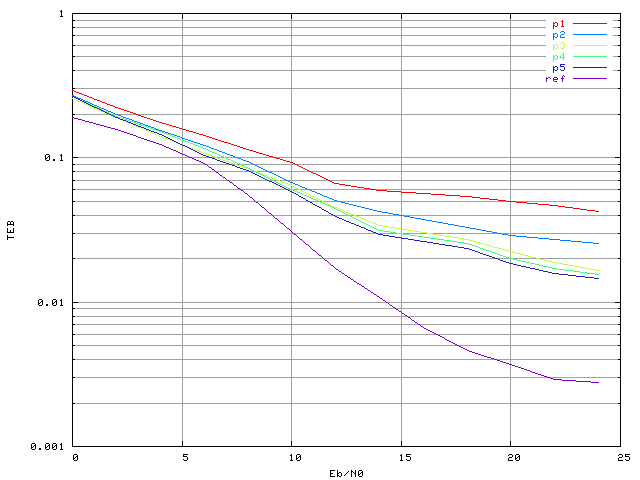
Suite à ces résultats surprenants, un perceptron-8 sans apprentissage a été créé, avec des poids fixés de telle manière que sa sortie soit égale à l'entrée. La simulation a bien donné une courbe confondue avec la courbe 'ref'. Le fait que l'on puisse créer un PMC en spécifiant les poids qui a de meilleures performances que tous les autres perceptrons prouve que le problème se situe au niveau de l'apprentissage. L'algorithme n'arrive pas à converger vers un jeu de paramètres correct pour le perceptron, et ceci pour toutes les architectures testées. Deux orientations sont alors possibles pour trouver une solution à ce problème. La première est d'essayer d'autres algorithmes d'apprentissage, ou d'utiliser des informations à priori sur le problème (telles que les règles de symétrie) pour aider l'apprentissage du réseau. La seconde est d'essayer un autre modèle de réseau de neurones. Cette dernière a été choisie, car les intermodulations qui apparaissent entre les porteuses sont des interférences d'ordre supérieur, ce qui laisse à penser que des réseaux d'ordre supérieur sont mieux adaptés au problème que les PMC.
[8] les critères d'arrêt utilisés couramment sont plutôt un arrêt de l'évolution des poids, ou de la performance d'apprentissage, ou encore une augmentation de l'erreur quadratique moyenne de validation. Comme aucun de ces phénomènes n'a pu être constaté dans nos simulations, nous avons choisi un nombre d'itérations fixe.