Différents réseaux d'ordre supérieur ont été simulés afin de réaliser un correcteur. Le réseau HPU (section 4.3) a été écarté en raison du grand nombre de dimensions de l'espace d'entrée, ce qui aurait engendré un très grand nombre de poids. Les réseaux Square-MLP (section 4.2) et Pi-Sigma (section 4.4) n'ont pas permis d'obtenir de résultats plus satisfaisants que les PMC, mais par contre le RPN (section 4.5) a montré les résultats plus intéressants, et c'est donc un correcteur basé sur cette architecture qui va être présenté.
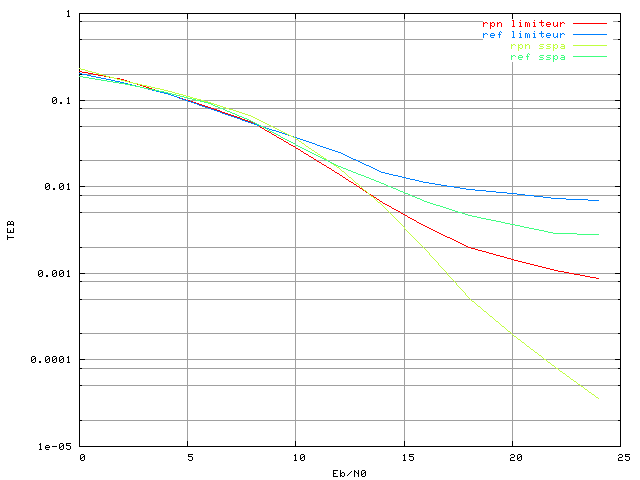
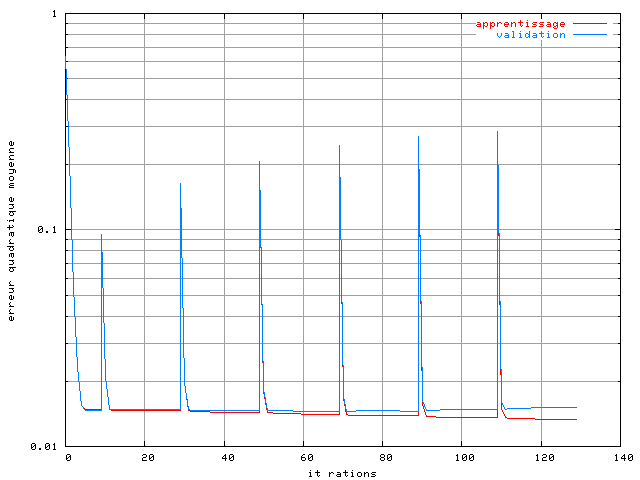
Les conditions sont les mêmes que pour le correcteur à base de perceptron. Nous avons utilisé la même base d'apprentissage : système OFDM à 4 porteuses avec une modulation MAQ16, une non-linéarité de type SSPA avec le paramètre p=2 et aucun bruit sur le canal. Dans un premier temps une base d'apprentissage de 256 symboles OFDM a été utilisée. La figure 3.19 montre l'évolution de la performance du RPN sur les bases d'apprentissage et de validation. L'algorithme d'optimisation est ici une descente de gradient adaptative, avec 200 itérations sur chaque ordre. On remarque une augmentation très élevée de l'erreur quadratique moyenne toutes les 200 itérations, ceci correspond à l'ajout au RPN d'un nouveau réseau pi-sigma, avec des poids initialisés aléatoirement. L'apprentissage d'un réseau RPN s'effectue en effet en plusieurs étapes successives, comme ceci était présenté dans le paragraphe 4.5.
Figure 3.19. Apprentissage d'un RPN dans un système OFDM à 4 porteuses avec un amplificateur SSPA, une modulation MAQ16, un recul de 0 dB et une base de 256 éléments sans bruit
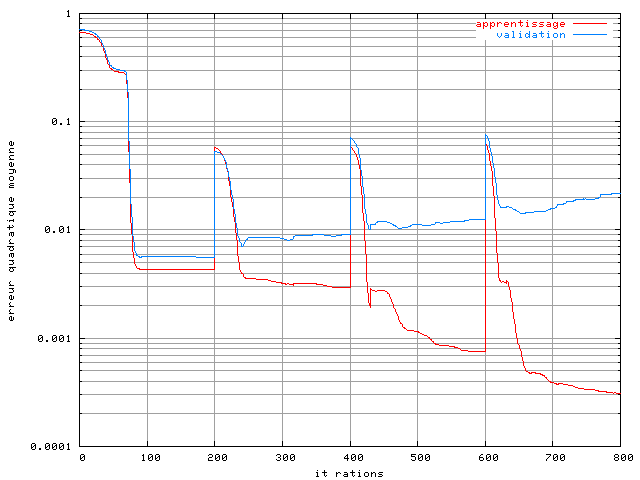
L'apprentissage a ici été stoppé à l'ordre 4. La courbe montre de manière évidente qu'il y a un surapprentissage, puisque l'erreur quadratique moyenne sur la base d'apprentissage diminue très rapidement, tandis que celle sur la base de validation augmente. Pour résoudre ce problème, une première méthode est de réduire la complexité du réseau. Cependant dans un réseau RPN ceci n'est pas possible, son architecture étant fixe. Le nombre de poids dépend simplement du nombre d'entrées et de sorties, ainsi que de l'ordre. La méthode qui a été plutôt choisie ici consiste à augmenter la taille de la base afin de permettre une meilleure généralisation du réseau. Nous l'avons augmentée progressivement, jusqu'à obtenir des résultats satisfaisants avec 16384 éléments :
Figure 3.20. Apprentissage d'un RPN dans un système OFDM à 4 porteuses avec un amplificateur SSPA, une modulation MAQ16, un recul de 0 dB et une base de 16384 éléments sans bruit
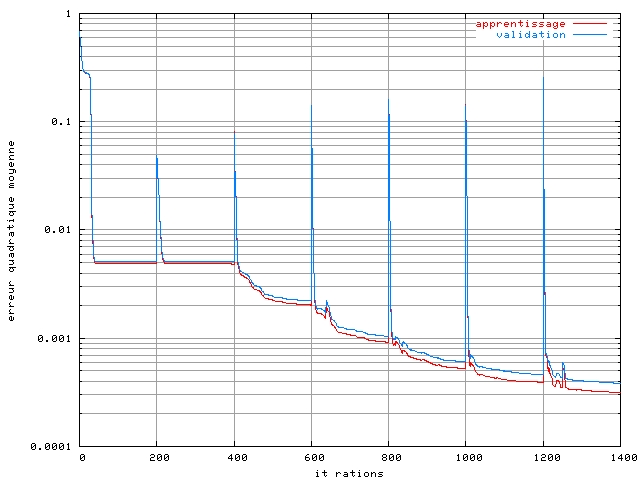
Cet apprentissage a demandé 1 heure et 50 minutes sur une station Sun Ultra 10 avec l'algorithme de descente de gradient. Pour l'accélérer nous avons utilisé l'algorithme de Levenberg Marquardt, qui peut converger en moins d'itérations, mais avec plus de calcul sur chaque itération. Sur la même base, nous avons pu réduire le nombre d'itérations à 20 par ordre. L'apprentissage a duré 14 minutes sur la même station Sun et la courbe est montrée figure 3.21 :
Figure 3.21. Apprentissage d'un RPN dans un système OFDM à 4 porteuses avec un amplificateur SSPA, une modulation MAQ16, un recul de 0 dB, une base de 16384 éléments sans bruit et un algorithme de Levenberg Marquardt
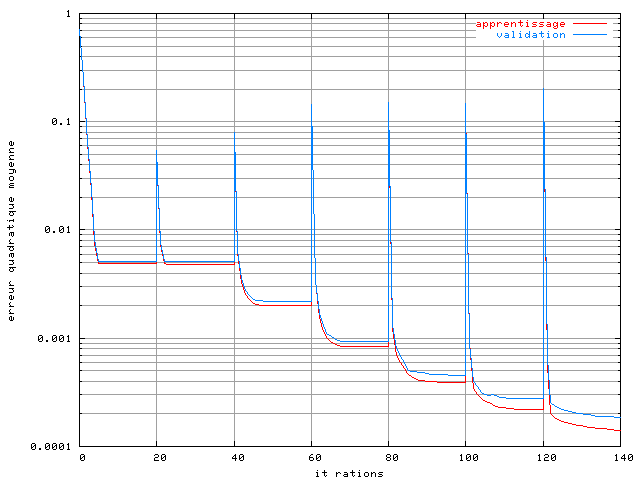
L'apprentissage a été arrêté à l'ordre 7 car pour des ordres supérieurs on ne constate plus de diminution de l'erreur quadratique moyenne. On constate bien sur cette courbe que le modèle réalisé par le réseau RPN est affiné à chaque fois que l'on ajoute un réseau pi-sigma. Le réseau est ensuite simulé dans la chaîne OFDM afin de mesurer le taux d'erreur binaire en sortie :
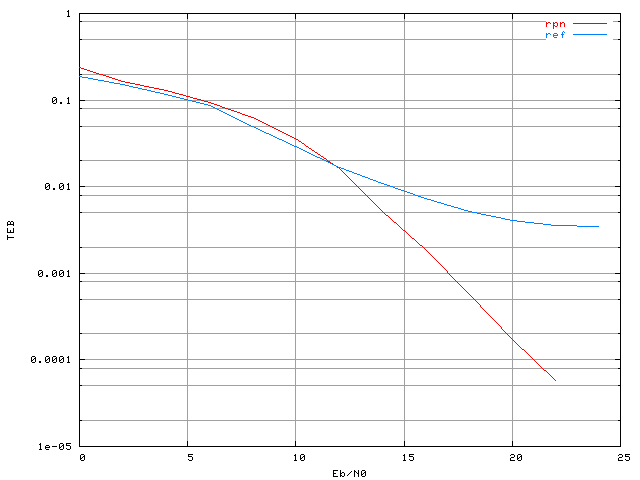
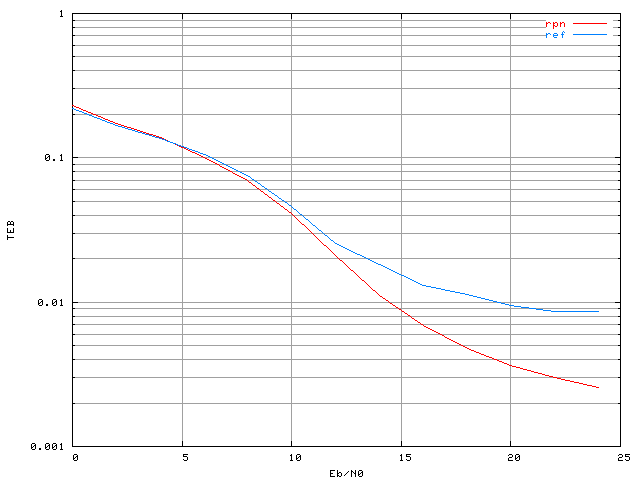
Figure 3.22. Taux d'erreur binaire d'un système OFDM à 4 porteuses avec une modulation MAQ16, un amplificateur SSPA, un recul de 0 dB et correcteur RPN (apprentissage sans bruit)
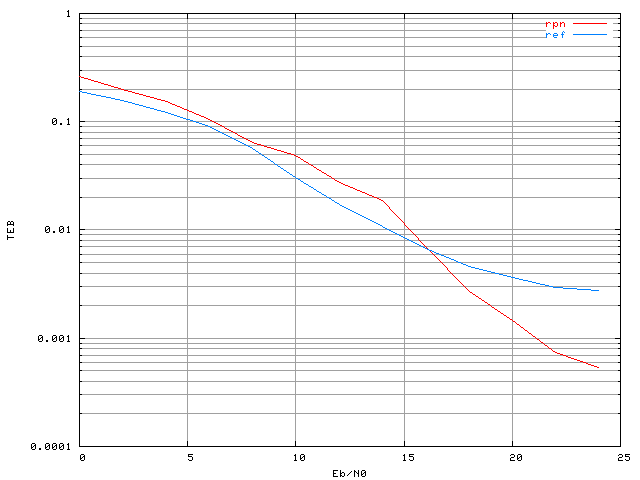
La courbe 'rpn' correspond à celle obtenue avec le correcteur RPN, et la courbe 'ref' est celle de référence, sans correcteur, mais toujours avec la non-linéarité. Le correcteur avec le réseau RPN n'est efficace qu'au dessus d'un certain rapport signal sur bruit (16 dB environ). Nous avions évoqué dans la section 2.2 qu'il était possible qu'il soit nécessaire d'ajouter du bruit lors de l'apprentissage pour augmenter l'immunité au bruit du réseau de neurones en utilisation après son apprentissage, c'est ce que nous allons illustrer maintenant.
Nous avons donc réalisé plusieurs apprentissages avec des rapports signal sur bruit différents, puis simulé tous les réseaux afin d'extraire le taux d'erreur binaire obtenu dans le système OFDM. Tous les autres paramètres sont identiques à ceux du dernier réseau RPN : 4 porteuses, modulation MAQ16, un amplificateur non linéaire SSPA avec le paramètre p=2, réseau RPN d'ordre 7, algorithme de Levenberg Marquardt, et 16384 exemples dans la base. Les courbes d'apprentissage des réseaux sont très similaires à celles de la figure 3.21, sauf l'erreur quadratique moyenne qui est plus élevée, à cause du bruit sur la base. La courbe figure 3.23 montre les taux d'erreur binaire avec tous ces réseaux :
Figure 3.23. Taux d'erreur binaire d'un système OFDM à 4 porteuses avec une modulation MAQ16, un amplificateur SSPA, un recul de 0 dB et correcteur RPN (apprentissage avec bruit)
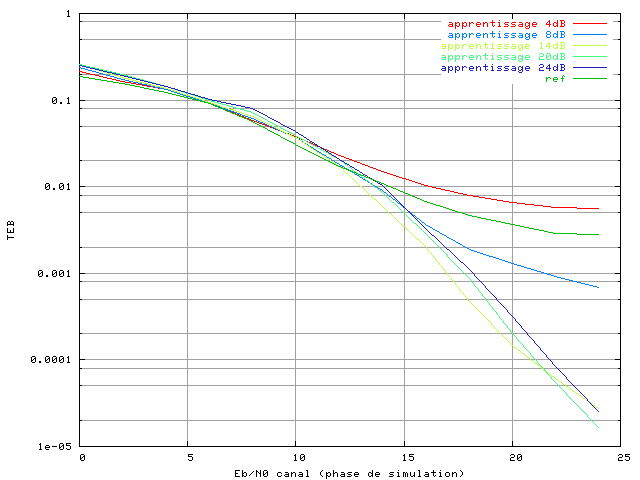
La courbe 'ref' est toujours la référence, et pour toutes
les autres courbes, le rapport signal sur bruit qui a été ajouté à la
base d'apprentissage est indiqué. On remarque que ce bruit ajouté à
la base d'apprentissage joue un très grand rôle dans les
performances du correcteur. Pour un rapport
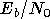 trop faible, comme 4 dB, le niveau de bruit est tellement élevé que
l'algorithme d'optimisation ne permet pas de trouver un réseau
de neurones avec de bonnes performances. En diminuant la puissance du
bruit, on améliore les
performances du
correcteur, et le taux d'erreur binaire est bien réduit. On remarque
que le réseau ayant appris avec
trop faible, comme 4 dB, le niveau de bruit est tellement élevé que
l'algorithme d'optimisation ne permet pas de trouver un réseau
de neurones avec de bonnes performances. En diminuant la puissance du
bruit, on améliore les
performances du
correcteur, et le taux d'erreur binaire est bien réduit. On remarque
que le réseau ayant appris avec 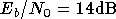 a les meilleurs performances quand il est simulé avec un canal
présentant un
inférieur à 21 dB. Mais ensuite, un réseau ayant appris avec moins de
bruit (un taux de 20 dB) a de meilleures performances.
L'interprétation de ces résultats étant difficile, une autre courbe
a été tracée figure 3.24 dans le
but de trouver le meilleur rapport signal sur bruit à utiliser pour
créer la base d'apprentissage. En ordonnée nous avons toujours le
taux d'erreur binaire, et en abscisse cette fois il s'agit du
rapport
de la base d'apprentissage. Les courbes sont tracées à
de en phase d'exploitation fixe.
a les meilleurs performances quand il est simulé avec un canal
présentant un
inférieur à 21 dB. Mais ensuite, un réseau ayant appris avec moins de
bruit (un taux de 20 dB) a de meilleures performances.
L'interprétation de ces résultats étant difficile, une autre courbe
a été tracée figure 3.24 dans le
but de trouver le meilleur rapport signal sur bruit à utiliser pour
créer la base d'apprentissage. En ordonnée nous avons toujours le
taux d'erreur binaire, et en abscisse cette fois il s'agit du
rapport
de la base d'apprentissage. Les courbes sont tracées à
de en phase d'exploitation fixe.
Figure 3.24. Taux d'erreur binaire d'un système OFDM à 4 porteuses (recul de 0 dB, amplificateur SSPA, modulation MAQ16) avec correcteur RPN (simulation à Eb/N0 fixe sur chaque courbe, apprentissage avec différents Eb/N0)
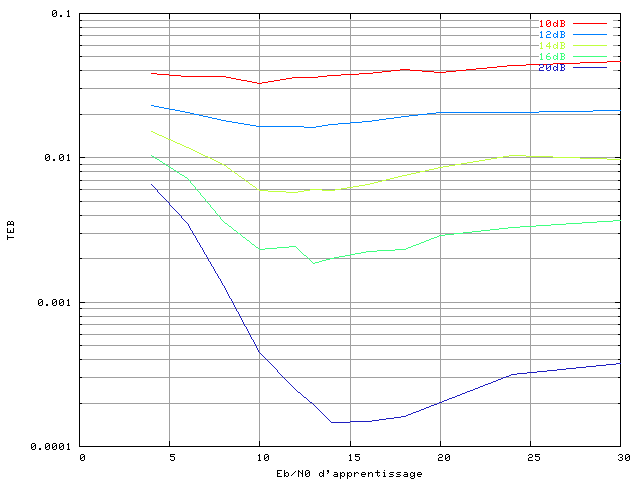
On remarque que quel que soit le rapport signal sur bruit en
simulation, ce sont les bases avec un rapport signal sur bruit situé
entre environ 10 et 20 dB qui permettent d'obtenir les meilleures
performances. Pour un
en exploitation de 10 dB, le minimum de la courbe d'erreur
correspond à une base d'apprentissage avec un
de 10 dB, et lorsque l'on augmente le rapport signal sur bruit en
exploitation, ce minimum augmente également jusqu'à atteindre 15 dB
pour un
en exploitation de 20 dB. Nous avons choisi
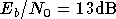 pour la base d'apprentissage, ce qui permet d'obtenir un taux
d'erreur binaire faible dans la plupart des cas simulés et
représente un bon compromis. C'est donc ce taux qui sert de
référence et qui sera toujours utilisé dans la constitution de bases
d'apprentissage pour ce correcteur RPN.
pour la base d'apprentissage, ce qui permet d'obtenir un taux
d'erreur binaire faible dans la plupart des cas simulés et
représente un bon compromis. C'est donc ce taux qui sert de
référence et qui sera toujours utilisé dans la constitution de bases
d'apprentissage pour ce correcteur RPN.
Figure 3.25. Taux d'erreur binaire d'un système OFDM à 4 porteuses avec une modulation MAQ16, un amplificateur SSPA, un recul de 0 dB et correcteur RPN (apprentissage avec Eb/N0=13 dB)
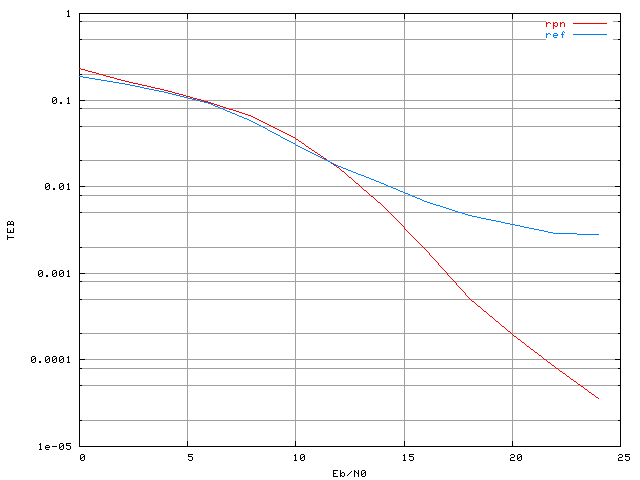
La figure 3.25 présente donc les
résultats avec le réseau RPN et la base d'apprentissage choisis.
Pour un taux d'erreur binaire de 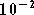 on mesure un gain apporté par le correcteur d'environ 1,5 dB. Pour
un taux d'erreur binaire de
on mesure un gain apporté par le correcteur d'environ 1,5 dB. Pour
un taux d'erreur binaire de 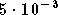 ,
ce gain est d'environ 4 dB. Pour un rapport
de 20 dB le taux d'erreur binaire est divisé par 19 grâce au réseau
de neurones. Ces résultats ont été publiés dans [TERT02] et [TERT03].
,
ce gain est d'environ 4 dB. Pour un rapport
de 20 dB le taux d'erreur binaire est divisé par 19 grâce au réseau
de neurones. Ces résultats ont été publiés dans [TERT02] et [TERT03].
Un des avantages des réseaux de neurones est leur capacité à s'adapter à différents problèmes. Nous avons donc entraîné puis simulé le même réseau RPN dans un système OFDM avec une non-linéarité différente. Dans un premier temps nous avons pris un amplificateur de type SSPA avec le paramètre p=3 (ce modèle sera noté SSPA3 dans le reste de ce mémoire), et comme on peut le constater après apprentissage le correcteur parvient toujours à corriger les non-linéarités de manière significative :
Figure 3.26. Taux d'erreur binaire d'un système OFDM à 4 porteuses avec une modulation MAQ16, un amplificateur SSPA3, un recul de 0 dB et correcteur RPN, (apprentissage avec Eb/N0=13 dB)
La courbe est comparable à celle obtenue avec le modèle SSPA
prenant p=2 (figure 3.25), nous constatons
les mêmes gains de 1,5 dB et 4 dB pour les taux d'erreur binaire
respectifs de
et 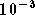 .
Pour un rapport
de 20 dB le taux d'erreur binaire est divisé par 24 avec le
correcteur. Enfin nous avons pris un
limiteur, et dans ce cas également le correcteur est efficace :
.
Pour un rapport
de 20 dB le taux d'erreur binaire est divisé par 24 avec le
correcteur. Enfin nous avons pris un
limiteur, et dans ce cas également le correcteur est efficace :
Figure 3.27. Taux d'erreur binaire d'un système OFDM à 4 porteuses avec correcteur RPN, limiteur avec un recul de 0 dB, modulation MAQ16, apprentissage avec Eb/N0=13 dB, et comparaison avec les résultats obtenus avec le modèle SSPA p=2
La courbe de référence (sans correcteur mais avec le limiteur) est
appelée 'ref limiteur', et celle obtenue avec le correcteur RPN
est appelée 'rpn limiteur'. Le gain apporté par le réseau de
neurones est de presque 5 dB pour un taux d'erreur binaire de
et de plus de 10 dB pour un taux d'erreur binaire de
.
Pour un rapport
de 20 dB le taux d'erreur binaire est divisé par 7 avec le
correcteur. Ainsi avec un nouvel apprentissage, le correcteur à RPN est
capable de s'adapter à des non-linéarités différentes. En pratique
ceci peut être intéressant dans une application mobile, dans laquelle le
récepteur peut se déplacer, et nécessiter une connexion avec un nouvel
émetteur lors d'un changement de zone. Si le nouvel émetteur possède
un amplificateur différent de l'ancien, il suffira au récepteur
d'effectuer un nouvel
apprentissage pour s'adapter, à condition que le temps et la
puissance de calcul requis par cette apprentissage soient compatibles
avec l'application voulue.
Les gains apportés
par le correcteur à taux d'erreur binaire fixé semblent indiquer que
le réseau est beaucoup plus efficace dans le cas du limiteur que les
autres cas, ce qui n'est pas forcément évident en regardant les
courbes. Dans la figure 3.27 nous avons
ajouté les résultats présentés figure 3.25
dans le cas d'une non linéarité de type SSPA avec p=2 (courbes
'ref sspa' et 'rpn sspa'). On peut remarquer que dans le
cas du limiteur la courbe du système sans correction présente une sorte
de plateau à un taux d'erreur binaire plus élevé que dans celui de
l'amplificateur SSPA, ce qui augmente les gains mesurés à taux
d'erreur binaire fixe. Ainsi pour comparer les performances du
correcteur basé sur un réseau de neurones dans des systèmes OFDM ayant
des caractéristiques différentes, la mesure du gain en taux d'erreur
binaire à rapport signal sur bruit fixe est plus fiable. Les mesures
présentées ont été faites à un rapport
de 20 dB, et le taux d'erreur binaire a été divisé par 7 dans le cas
du limiteur et 19 dans le cas de l'amplificateur SSPA avec p=2, ce
qui est plus conforme à ce que l'on constate graphiquement.
Après avoir obtenu des gains significatifs avec le réseau RPN sur un système à 4 porteuses dans les conditions évoquées précédemment, nous avons fait des essais avec 8 et 16 porteuses. Considérons tout d'abord le cas avec 8 porteuses : nous avons construit une base d'apprentissage de 32768 symboles OFDM, avec un rapport signal sur bruit de 13 dB et entraîné le un RPN par un algorithme de Levenberg-Marquardt. La figure 3.28 montre les évolutions des erreurs d'apprentissage et de validation au fur et à mesure des itérations :
Figure 3.28. Apprentissage d'un RPN appliqué à un système OFDM à 4 porteuses avec un amplificateur SSPA, une modulation MAQ16, un recul de 0 dB et une base de 32768 éléments avec bruit (Eb/N0=13 dB)
Comme pour l'apprentissage avec 4 porteuses (figure 3.21), l'erreur quadratique moyenne ne diminue pas lorsque l'on ajoute des réseaux pi-sigma d'ordre supérieur à 7, et nous nous sommes donc arrêtés à cet ordre. Le réseau RPN ainsi entraîné est ensuite simulé dans un système OFDM :
Figure 3.29. Taux d'erreur binaire sur un système OFDM à 8 porteuses avec une modulation MAQ16, un amplificateur SSPA, un recul de 0 dB et correcteur RPN (apprentissage avec Eb/N0=13 dB)
On constate un gain de 5 dB pour un taux d'erreur binaire de
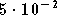 ,
mais les deux courbes sont tout de même plus proches que lorsqu'il
n'y avait que 4 porteuses, comme on peut le voir sur la figure 3.30 qui présente les deux résultats
montré figures 3.25 et 3.29. A titre de comparaison la courbe théorique
sans non-linéarités est également présente.
,
mais les deux courbes sont tout de même plus proches que lorsqu'il
n'y avait que 4 porteuses, comme on peut le voir sur la figure 3.30 qui présente les deux résultats
montré figures 3.25 et 3.29. A titre de comparaison la courbe théorique
sans non-linéarités est également présente.
Figure 3.30. Comparaison des résultats obtenus avec le correcteur RPN simulé dans des systèmes OFDM à 4 et 8 porteuses, avec un amplificateur SSPA, un recul de 0 dB et une modulation MAQ16
Pour un rapport
de 20 dB le taux d'erreur binaire est divisé par 3 seulement, ce qui
est effectivement bien moins que le rapport 19 mesuré dans le système
avec 4 porteuses. Pour le système avec 16 porteuses nous avons à nouveau
doublé la taille de la base, portée donc à 65536 éléments.
L'apprentissage du réseau est plus difficile :
Figure 3.31. Apprentissage d'un RPN sur un système OFDM à 16 porteuses avec un amplificateur SSPA, une modulation MAQ16, un recul de 0 dB et une base de 65536 éléments avec bruit (Eb/N0=13 dB)
On constate en effet que l'erreur quadratique moyenne sur la base d'apprentissage ne diminue pas lors de chaque ajout d'un réseau pi-sigma, et celle de validation augmente même à partir de l'ordre 4. Les algorithmes d'apprentissage (descente de gradient et Levenberg-Marquardt) ne parviennent pas à affiner le modèle et la performance à la fin de l'apprentissage reste la même que celle obtenue avec un réseau pi-sigma d'ordre 1, c'est à dire d'un système linéaire. On peut donc supposer que le correcteur ainsi obtenu ne pourra pas diminuer le taux d'erreur binaire par rapport à un système classique. Ceci est confirmé par la simulation :
Figure 3.32. Taux d'erreur binaire avec le correcteur RPN appliqué à un système OFDM à 16 porteuses avec une modulation MAQ16, un amplificateur SSPA, un recul de 0 dB et correcteur RPN (apprentissage avec Eb/N0=13 dB)
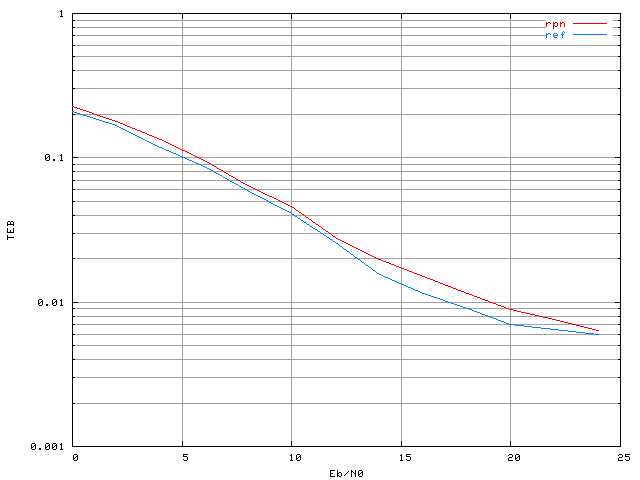
Le taux d'erreur est plus élevé avec le correcteur RPN (courbe 'rpn') que sans correcteur (courbe 'ref'). Nous avons utilisé diverses méthodes pour améliorer l'apprentissage : augmenter la taille de la base d'apprentissage, réduire le bruit sur la base, prendre une modulation plus simple (MAQ4) et revenir à une descente de gradient adaptative. Aucune de ces méthodes n'a permis d'améliorer les performances du correcteur. Comme pour les PMC, dans ce cas là l'algorithme d'apprentissage ne permet pas de converger vers un réseau ayant les caractéristiques recherchées. Nous constatons le même problème lorsque le nombre de porteuses est supérieur à 16, des tests ayant également été réalisés avec 32 et 48 porteuses.
Plusieurs voies de recherches peuvent être explorées pour tenter de résoudre le problème. Un travail sur l'algorithme d'apprentissage lui-même, avec par exemple une meilleure utilisation des symétries, ou une optimisation de la constitution de la base. Une autre voie qui pourrait être prometteuse est la famille de réseaux de neurones SVM (Support Vector Machines) [VAPN98]. Un réseau SVM peut avoir de bonnes performances dans un espace d'entrées à grand nombre de dimensions, et ne présente pas les problèmes d'apprentissage des PMC et autres réseaux d'ordre supérieur dus à la présence de minimums locaux. Le principe d'un réseau SVM est de s'appuyer sur quelques exemples de la base, les vecteurs de support, pour calculer la fonction de sortie. Un algorithme permet de sélectionner les exemples les plus significatifs, situés généralement à la frontière entre deux zones différentes de l'espace d'entrée. Ces deux axes n'ont pas été étudiés.
Une autre méthode qui peut être utilisée est de faire un traitement des données avant de les transmettre au réseau de neurones. C'est cette démarche qui a été suivie, en le plaçant dans le domaine temporel, comme nous le verrons dans le chapitre suivant.