Pour simuler un système OFDM, l'outil SPW (Signal Processing Workshop) de Cadence a été choisi en raison de ses performances au niveau du temps de calcul et de sa souplesse. Deux modèles d'amplificateurs ont été employés dans les différentes simulations. L'amplificateur SSPA (présenté en *) qui représente bien les amplificateurs à semi-conducteurs utilisé en radio mobile, et le limiteur (présenté en *), qui lui représente bien les amplificateurs radio munis d'une prédistorsion ou ceux utilisés pour les liaisons filaires de type ADSL.
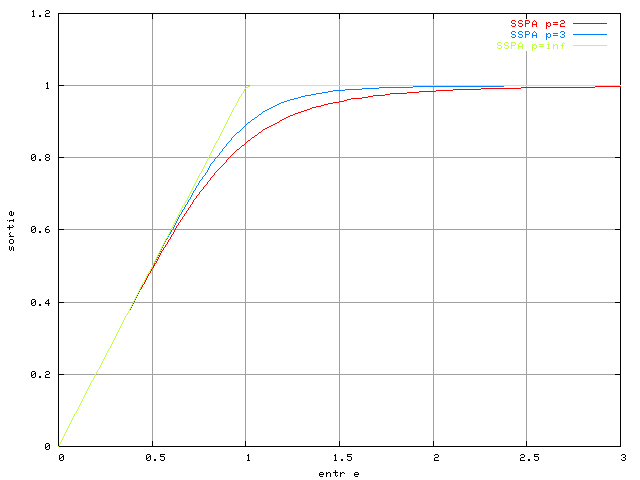
Le modèle SSPA comporte un paramètre
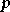 qui
permet de régler la forme de la réponse de l'amplificateur. Nous
avons utilisé les valeurs 2 et 3 dans nos simulations, ce qui correspond
le plus aux amplificateurs réels [RAPP91]. La courbe figure 3.6 montre la réponse d'un tel
amplificateur, en représentant le module de l'entrée en abscisse et
celui de la sortie en ordonnée. Les courbes pour
qui
permet de régler la forme de la réponse de l'amplificateur. Nous
avons utilisé les valeurs 2 et 3 dans nos simulations, ce qui correspond
le plus aux amplificateurs réels [RAPP91]. La courbe figure 3.6 montre la réponse d'un tel
amplificateur, en représentant le module de l'entrée en abscisse et
celui de la sortie en ordonnée. Les courbes pour
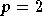 et
et
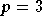 sont montrées, ainsi que celle pour
sont montrées, ainsi que celle pour 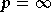 ,
ce qui correspond au modèle du limiteur. La non-linéarité de phase
n'est pas représentée ici, car avec le modèle SSPA elle est nulle,
et ainsi aucun déphasage n'est introduit par la non-linéarité de
l'amplificateur.
,
ce qui correspond au modèle du limiteur. La non-linéarité de phase
n'est pas représentée ici, car avec le modèle SSPA elle est nulle,
et ainsi aucun déphasage n'est introduit par la non-linéarité de
l'amplificateur.
On rappelle que la sévérité de la non-linéarité peut être représentée par le recul, ou Input Back Off en anglais (*) et qui est le rapport entre la puissance de saturation ramenée à l'entrée et la puissance moyenne du signal. Plus le recul est élevé, moins les distorsions linéaires sont importantes.
Dans un premier temps pour tester les différentes
architectures neuronales un canal très simple a été simulé. Il
s'agit d'un
canal gaussien, qui
n'est pas sélectif en fréquence. Dans ce canal le signal est propagé
sans distorsion, et un
bruit blanc additif gaussien est ajouté. Le rapport signal sur bruit (RSB ou
SNR pour Signal to Noise Ratio en anglais) est une mesure relative du
bruit, égale (à un logarithme près) au rapport entre la puissance
moyenne du signal et celle du bruit blanc gaussien. Cependant dans le
domaine des télécommunications ce qui est le plus significatif pour le
choix d'une architecture ce n'est pas simplement la puissance
d'émission du signal, mais plutôt l'énergie dépensée par unité
de quantité d'information. Un autre critère est donc utilisé, noté
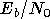 et défini *. On rappelle que sa
valeur est le rapport entre l'énergie dépensée pour émettre un bit
d'information et la densité spectrale du bruit. Il est donc fonction
du rapport signal sur bruit, mais également du
rendement du
codage canal et de la
modulation. De plus il est proportionnel au RSB, et lorsqu'il est
exprimé en dB, est égal au RSB ajouté d'un facteur que l'on peut
calculer à l'aide du rendement du code et du nombre de bits par
symbole.
et défini *. On rappelle que sa
valeur est le rapport entre l'énergie dépensée pour émettre un bit
d'information et la densité spectrale du bruit. Il est donc fonction
du rapport signal sur bruit, mais également du
rendement du
codage canal et de la
modulation. De plus il est proportionnel au RSB, et lorsqu'il est
exprimé en dB, est égal au RSB ajouté d'un facteur que l'on peut
calculer à l'aide du rendement du code et du nombre de bits par
symbole.
Pour constituer une base d'apprentissage, on se sert d'une simulation du système OFDM comprenant le canal ainsi que son égalisation. Un générateur aléatoire produit des informations binaires, et l'on stocke pour chaque symbole OFDM simulé le symbole émis et le symbole reçu. Les symboles reçus seront fournis comme entrées du réseau de neurones lors de l'apprentissage, et le symbole émis sera donné comme réponse voulue. Le réseau va ainsi apprendre à inverser la non-linéarité.
Plusieurs paramètres sont importants pour la génération de la base d'apprentissage. Tout d'abord les caractéristiques de la modulation OFDM : en effet les paramètres tels que le nombre de porteuses, le codage binaire à symbole ainsi que le recul et le modèle de l'amplificateur peuvent tous modifier le comportement fréquentiel de la non-linéarité, et donc la fonction que doit réaliser le réseau de neurones. Dans les présentations de résultats, ces paramètres seront systématiquement indiqués. Ensuite le nombre d'exemples dans la base d'apprentissage est également très significatif. Trop peu d'exemples et l'on risque un surapprentissage du réseau, trop d'exemples et la quantité de mémoire et le temps nécessaire pour créer la base d'apprentissage deviennent prohibitifs.
Enfin un dernier paramètre important est la puissance de
bruit du canal. En effet
lorsqu'il est utilisé dans la chaîne de communication OFDM, le canal
ajoute du bruit au signal, et donc le réseau de neurones doit travailler
avec un signal bruité en entrée. Pour son apprentissage, on a donc le
choix entre donner au réseau une base sans bruit, ou bien avec plus ou
moins de bruit que lors de son exploitation. On peut supposer
qu'avec une base sans bruit le réseau apprend plus facilement la
fonction à réaliser. Cependant si l'on veut qu'il ait une grande
immunité au
bruit, il est nécessaire de lui faire apprendre avec du bruit. On peut
s'en rendre compte sur un exemple simple : supposons que
l'on soit en présence d'un canal parfait, sans aucune distorsion
ni linéaire ni non linéaire. On veut apprendre à un réseau un décodage
de type MAQ4, et en particulier celui qui va décoder la partie réelle du
signal. Le réseau doit fournir -1 en sortie si la partie réelle du
signal est négative, et +1 si elle est positive. Ce système peut être
réalisé très simplement sans réseau de neurones à l'aide d'un
seuil de décision, mais nous allons étudier ce réseau afin de comprendre
l'influence du bruit. La figure 3.7
montre la modulation MAQ4 avec un bon rapport signal sur bruit (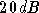 ) et la
réponse du réseau de type
sigmoïde qui pourrait réaliser la fonction voulue.
) et la
réponse du réseau de type
sigmoïde qui pourrait réaliser la fonction voulue.
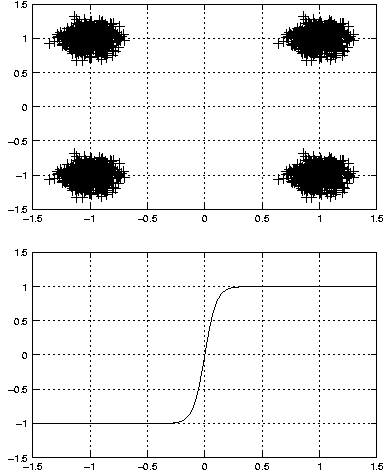
On constate cependant qu'il n'y a aucun exemple dans la base d'apprentissage dont l'abscisse est comprise entre -0.6 et 0.6. L'algorithme d'apprentissage peut donc aboutir a des réseaux qui réalisent des fonctions légèrement différentes, avec une sigmoïde ayant une pente plus douce, ou une sigmoïde décalée par exemple comme dans la figure 3.8 :
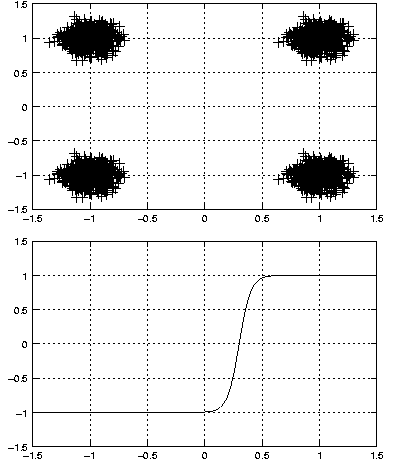
Théoriquement cette solution n'est pas optimale, même avec
cette base d'apprentissage, car la sigmoïde n'atteint jamais
exactement les valeurs -1 et 1, et l'erreur quadratique moyenne à la
fin de l'apprentissage est légèrement plus élevée dans ce cas que le
précédent, figure 3.7. Cependant en
pratique avec des algorithmes tels que la descente de gradient il est possible
d'obtenir un tel résultat. Le réseau ainsi formé aura aussi une
erreur d'apprentissage très faible, avec des valeurs en sortie
d'environ -1 pour les exemples de la base situés à gauche et 1 pour
ceux situés à droite. Supposons que le réseau soit ensuite confronté à
des données avec un rapport signal sur bruit inférieur, comme par
exemple 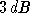 dans l'exemple suivant, figure 3.9. Du fait du décalage de la
sigmoïde, pour des symboles qui auraient dû provoquer une sortie à 1, le
réseau va en fait donner en sortie une valeur entre -1 et 1.
L'erreur du réseau en utilisation sera donc plus élevée :
dans l'exemple suivant, figure 3.9. Du fait du décalage de la
sigmoïde, pour des symboles qui auraient dû provoquer une sortie à 1, le
réseau va en fait donner en sortie une valeur entre -1 et 1.
L'erreur du réseau en utilisation sera donc plus élevée :
Si l'apprentissage du réseau avait été fait avec la base ayant
un RSB de
au lieu de ,
l'algorithme aurait sélectionné une sigmoïde plus centrée, car
celle-ci aurait engendré une erreur d'apprentissage plus faible que
la sigmoïde décalée que l'on voit ci-dessus. On en déduit donc
qu'il faudrait que la base d'apprentissage soit constituée avec
un bruit au moins aussi puissant que celui qui sera présent lors de
l'utilisation du réseau de neurones. Ceci sera également vérifié
expérimentalement.
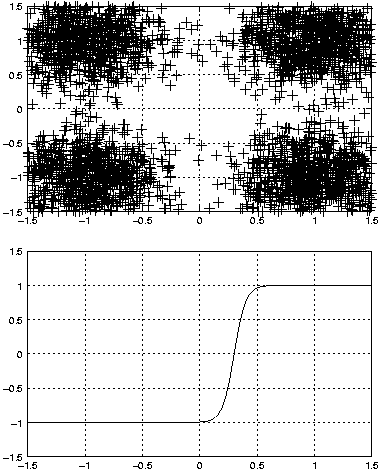
Une fois la base d'apprentissage constituée, différentes architectures de réseaux de neurones sont testées et comparées. La fonction d'activation de la dernière couche des réseaux doit cependant être adaptée à la modulation que l'on désire. Par exemple la sigmoïde est adaptée aux modulations de type MAQ4, comme on vient de l'illustrer dans les figures précédentes. Pour une modulation plus complexe, comme une MAQ16, il est possible de choisir une sigmoïde présentant deux plateaux supplémentaires, qui permettront de guider le réseau vers les 4 sorties différentes que l'on désire qu'il produise. Par exemple :
Figure 3.10. Exemple de fonction d'activation adaptée à une modulation MAQ16, avec un rapport signal sur bruit de 20 dB
De telles fonctions d'activation ont déjà été crées et étudiées dans le contexte des télécommunications et des travaux montrent qu'elles sont bien adaptées à ces modulations [MAN94], [BALA95].
Dans les exemples précédents la fonction que doit réaliser le réseau de neurones est évidente, ce qui permet d'illustrer facilement le problème posé par le bruit et l'adaptation de la fonction d'activation à la modulation. En pratique sur un canal multiporteuses avec une non-linéarité la tâche que devra réaliser le réseau est bien plus complexe. En effet les non-linéarités vont induire des perturbations entre les différentes porteuses (voir section 1.2) et la séparation entre les différents symboles de la constellation ne sera pas si évidente à accomplir.
L'erreur du réseau de neurones à la fin de son apprentissage
peut nous renseigner sur ses capacités à réduire les effets des non
linéarités, mais le seul critère objectif qui nous permet de mesurer ses
performances est le
taux d'erreur binaire dans une chaîne de transmission OFDM complète.
Donc une fois l'apprentissage terminé, on
simule à nouveau un système OFDM avec le correcteur, et l'on mesure
le taux d'erreur binaire (rapport entre le nombre de bits erronés et
le nombre de bits transmis) de la transmission en fonction du rapport
signal sur bruit ().
Ces résultats sont présentés sous forme d'une courbe avec le taux
d'erreur binaire en ordonnée et le rapport signal sur bruit en
abscisse. Une courbe seule n'est pas très utile en elle-même, mais
c'est la comparaison entre deux courbes qui est intéressante. La
figure 3.11 montre un exemple de
résultat obtenu avec un correcteur qui sera présenté plus tard dans
cette thèse :
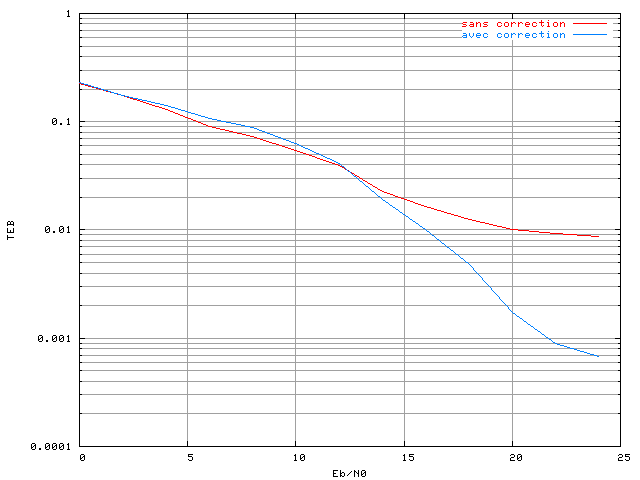
Le système comporte 48 porteuses, avec une modulation MAQ16 et un
recul de l'amplificateur de 0 dB. Le taux d'erreur est plus
faible avec le correcteur, celui-ci réduit donc les effets des
non-linéarités, à partir d'un certain rapport signal sur bruit.
Cette courbe peut être exploitée de deux façons. On peut se fixer un
rapport signal sur bruit, et quantifier le gain sur le taux. Par exemple
à 20 dB, le nombre d'erreurs sur la transmission est divisé par 5.
Mais une autre interprétation plus intéressante est faite à taux
d'erreur binaire constant. En effet en pratique le taux d'erreur
voulu sur une transmission est fixée par l'application : on
veut pouvoir garantir un certain taux. Si l'on se fixe un objectif
de 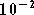 pour le taux d'erreur binaire, on constate une différence de 4 dB
sur le rapport signal sur bruit. Ceci veut dire que le correcteur permet
d'utiliser un signal avec une puissance inférieure de 4 dB, avec les
mêmes performances. On peut donc diviser la puissance de
l'amplificateur par un facteur de plus de 2,5 grâce au correcteur,
sans changer la qualité de la transmission. Cet aspect est le plus
intéressant pour une application donnée, car un amplificateur moins
puissant coûte moins cher et consomme moins d'énergie. La valeur du
taux d'erreur binaire choisie pour cette comparaison,
,
correspond souvent au point à partir duquel le code canal commence à
être efficace en terme de correction d'erreurs, et est donc un point
intéressant pour l'étude de la compensation des effets des
non-linéarités.
pour le taux d'erreur binaire, on constate une différence de 4 dB
sur le rapport signal sur bruit. Ceci veut dire que le correcteur permet
d'utiliser un signal avec une puissance inférieure de 4 dB, avec les
mêmes performances. On peut donc diviser la puissance de
l'amplificateur par un facteur de plus de 2,5 grâce au correcteur,
sans changer la qualité de la transmission. Cet aspect est le plus
intéressant pour une application donnée, car un amplificateur moins
puissant coûte moins cher et consomme moins d'énergie. La valeur du
taux d'erreur binaire choisie pour cette comparaison,
,
correspond souvent au point à partir duquel le code canal commence à
être efficace en terme de correction d'erreurs, et est donc un point
intéressant pour l'étude de la compensation des effets des
non-linéarités.