Le but des réseaux d'ordre supérieur est d'améliorer les performances du perceptron sans recourir à un grand nombre de couches cachées ou de neurones. Les perceptrons monocouche sont en effets très limités dans leurs capacités d'apprentissage, et dans la plupart des applications une ou plusieurs couches cachées sont nécessaires pour obtenir une approximation avec la précision voulue. L'inconvénient est la plus grande complexité du réseau et surtout un temps d'apprentissage plus long. Une autre solution, présentée ici, est de créer un réseau de neurones capable de prendre en compte les corrélations d'ordre supérieur entre les entrées. Ou vu autrement il peut s'agir de combiner l'approche locale des GRBF et l'approche globale des PMC grâce à des noyaux polynomiaux. Les possibilités d'approximation du réseau de neurones sont plus importantes, tout en réduisant le nombre de neurones et de couches, et donc d'éviter de rendre l'apprentissage plus long. Plusieurs moyens existent et font l'objet de cette section.
Une première solution est de créer des entrées supplémentaires à un PMC, en calculant les carrés des entrées de départ. Cette architecture se nomme SQUARE-MLP (SQuare Unit Augmented, Radially Extended, MultiLayer Perceptron).
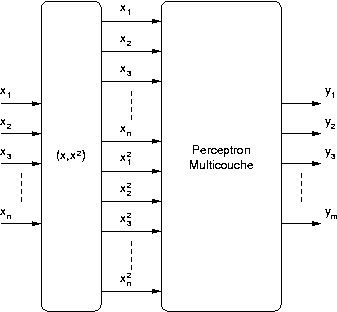
A partir du
vecteur d'entrée  on construit un nouveau vecteur
on construit un nouveau vecteur  .
Ce vecteur est ensuite donné comme entrée à un PMC classique. Le vecteur
donné en entrée du perceptron a une dimension deux fois plus grande que
celui d'origine, et donc le perceptron possède deux fois plus de
poids par neurone que s'il était utilisé seul. Cependant
l'apport de ces entrées supplémentaires permet au réseau de réaliser
une plus grande variété d'approximations avec un petit nombre de
neurones. Considérons la fonction représentée figure 2.19 (comme précédemment, l'axe
vertical est la sortie du réseau et les deux axes horizontaux sont ses
deux entrées) :
.
Ce vecteur est ensuite donné comme entrée à un PMC classique. Le vecteur
donné en entrée du perceptron a une dimension deux fois plus grande que
celui d'origine, et donc le perceptron possède deux fois plus de
poids par neurone que s'il était utilisé seul. Cependant
l'apport de ces entrées supplémentaires permet au réseau de réaliser
une plus grande variété d'approximations avec un petit nombre de
neurones. Considérons la fonction représentée figure 2.19 (comme précédemment, l'axe
vertical est la sortie du réseau et les deux axes horizontaux sont ses
deux entrées) :
Figure 2.19. Fonction réalisée par un réseau Square-MLP simple (2 entrées, une couche cachée de 2 neurones, une sortie)

Cette fonction est complexe à réaliser aussi bien par un réseau GRBF qu'un perceptron multicouches. En effet le réseau GRBF sera capable d'approximer la partie de droite avec un seul neurone, mais nécessitera un grand nombre de neurones pour approximer la partie gauche. Au contraire un perceptron multicouches pourra réaliser la partie gauche avec un seul neurone mais en nécessitera un grand nombre pour la partie droite. Avec un réseau Square-MLP, une couche cachée composée de deux neurones suivie d'une couche de sortie avec un neurone pourra approximer cette fonction avec de très bonnes performances.
Ce réseau a été testé dans un grand nombre de cas aussi bien théoriques que pratiques, et présente souvent de meilleures performances que les autres réseaux de neurones, avec une complexité moindre, en particulier dans les cas des fonctions présentant des variations à la fois sur de petites régions locales et sur des grandes divisions de l'espace d'entrée, comme dans le cas de la fonction ci-dessus [FLAK98].
Les réseaux Square-MLP peuvent être mis en oeuvre très rapidement et simplement, puisque les algorithmes déjà étudiés et implémentés pour les PMC peuvent être appliqués aux Square-MLP. La seule modification à faire est le calcul des entrées supplémentaires.
Le réseau HPU (Higher-order Processing Unit) utilise le même principe que le SQUARE-MLP, mais en calculant toutes les corrélations d'ordre supérieur entre les entrées, jusqu'à un certain ordre. Une sortie d'un réseau HPU est de la forme [GILE94] :
où 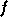 est la
fonction d'activation, linéaire ou de forme sigmoïde. Dans le cas
d'un réseau d'ordre supérieur une fonction d'activation en
sigmoïde ou tangente hyperbolique n'est pas obligatoire, car même
avec une fonction
linéaire la fonction effectuée par le réseau est polynomiale
et permet d'approximer de nombreuses fonctions. Ainsi son choix va
dépendre de l'application. L'ordre
du réseau est le degré du terme de plus haut degré. La réalisation
d'un réseau HPU peut s'inspirer de celle d'un
SQUARE-MLP :
est la
fonction d'activation, linéaire ou de forme sigmoïde. Dans le cas
d'un réseau d'ordre supérieur une fonction d'activation en
sigmoïde ou tangente hyperbolique n'est pas obligatoire, car même
avec une fonction
linéaire la fonction effectuée par le réseau est polynomiale
et permet d'approximer de nombreuses fonctions. Ainsi son choix va
dépendre de l'application. L'ordre
du réseau est le degré du terme de plus haut degré. La réalisation
d'un réseau HPU peut s'inspirer de celle d'un
SQUARE-MLP :
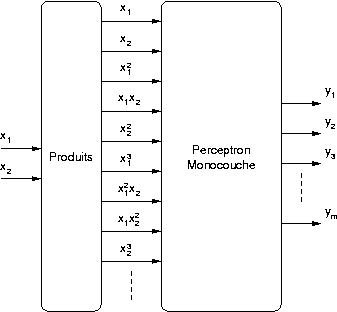
En effet l'équation (2.25) correspond à la
sortie d'un perceptron monocouche auquel on fournit en entrée tous
les produits possibles entre les entrées jusqu'à l'ordre du
réseau HPU. Comme pour le SQUARE-MLP, il est donc possible
d'utiliser les algorithmes existants pour le perceptron, et
d'ajouter simplement un module qui calcule ces produits avant de les
fournir au réseau de neurones. Si la fonction
est
linéaire les poids peuvent être déterminés plus simplement avec des
moindres
carrés.
Il est possible de créer un réseau multicouches dont chaque couche est constituée d'un HPU. Ceci dit en pratique cette approche rend le réseau compliqué et présente moins d'intérêt face à un PMC.
L'inconvénient du HPU réside dans le
nombre de poids
nécessaire. Celui-ci évolue de manière exponentielle avec le nombre
d'entrées 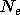 et l'ordre du réseau HPU
et l'ordre du réseau HPU 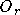 .
En effet, on peut montrer que ce nombre de poids est égal à
[JOYD92] :
.
En effet, on peut montrer que ce nombre de poids est égal à
[JOYD92] :
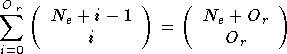
où () est la notation combinatoire. Ce nombre de poids est donc
égal au nombre de combinaisons de
éléments parmi 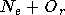 .
Donc cette architecture ne peut être utilisée en pratique qu'avec un
faible nombre d'entrées et pour des ordres peu élevés. Mais dans ces
cas il présente quelques avantages, tels qu'un apprentissage rapide
(ce réseau n'a pas de couche cachée) et une bonne adaptation aux
problèmes présentant des
invariances géométriques [GILE94].
.
Donc cette architecture ne peut être utilisée en pratique qu'avec un
faible nombre d'entrées et pour des ordres peu élevés. Mais dans ces
cas il présente quelques avantages, tels qu'un apprentissage rapide
(ce réseau n'a pas de couche cachée) et une bonne adaptation aux
problèmes présentant des
invariances géométriques [GILE94].
Le réseau
Pi-Sigma est une réponse au problème du nombre important de poids du
réseau HPU lorsque le nombre d'entrées ou l'ordre augmente. Un
réseau Pi-Sigma ne comporte qu'une sortie scalaire, mais on peut
créer un réseau avec 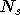 sorties en dupliquer le réseau
fois, chacun calculant une sortie. La sortie d'un réseau Pi-Sigma
est donnée par [SHIN91] :
sorties en dupliquer le réseau
fois, chacun calculant une sortie. La sortie d'un réseau Pi-Sigma
est donnée par [SHIN91] :
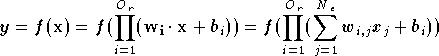
où
est la
fonction d'activation (linéaire ou non) et
est l'ordre du réseau. Comme pour le PMC (*), le biais sera considéré comme un poids
supplémentaire, lié à une entrée toujours à 1. La sortie est fonction
d'un produit de sommes, d'où le nom Pi-Sigma. L'intérêt du
réseau pi-sigma est le nombre réduit de poids par rapport à un HPU. En
effet, celui-ci est égal à :
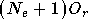
Un réseau pi-sigma est donc mieux adapté qu'un HPU pour des systèmes avec un grand nombre d'entrées, ou si l'on veut faire intervenir des corrélations d'ordre élevé entre les entrées.
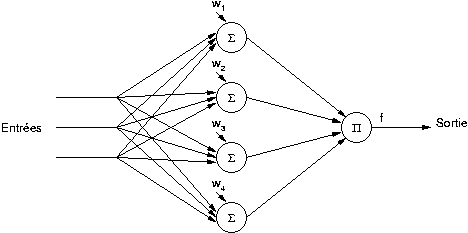
Le réseau Pi-Sigma peut être décomposé en deux
couches. La première
couche est composée de
neurones, chaque neurone effectuant une somme pondérée des entrées et y
ajoutant un biais. Dans la seconde couche un seul neurone est présent,
et celui-ci calcule le produit des sorties des neurones de la première
couche, y applique la fonction d'activation, et sa sortie est celle
du réseau. Seuls les neurones de la première couche ont des
poids ajustables.
L'apprentissage
d'un réseau
Pi-Sigma peut se faire avec un algorithme de descente de gradient, mais
celui-ci nécessite quelques modifications, à cause du produit réalisé
par le neurone de la seconde couche. Différents algorithmes sont étudiés
en détail dans [JOYD92],
et seul le principe de l'un d'entre eux sera évoqué ici. Nous
appellerons 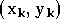 les éléments de la base d'apprentissage,
les éléments de la base d'apprentissage,
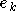 les erreurs correspondantes et
les erreurs correspondantes et  la performance (une
erreur quadratique moyenne). Comme pour le PMC nous considérons que le
biais est un poids
supplémentaire associé à une entrée à 1, et donc celui-ci n'apparaît
plus dans les formules suivantes. Si l'on applique l'algorithme
de
descente du gradient à ce réseau (équations (A.1) et (A.2)) on
obtient pour les mises à jour des poids :
la performance (une
erreur quadratique moyenne). Comme pour le PMC nous considérons que le
biais est un poids
supplémentaire associé à une entrée à 1, et donc celui-ci n'apparaît
plus dans les formules suivantes. Si l'on applique l'algorithme
de
descente du gradient à ce réseau (équations (A.1) et (A.2)) on
obtient pour les mises à jour des poids :
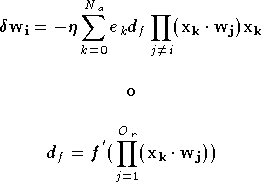
Si l'on applique directement l'algorithme de descente du
gradient au réseau Pi-Sigma, c'est à dire si l'on ajoute les
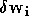 à tous les poids à chaque itération, on constate que l'algorithme ne
converge que pour des faibles valeurs de
à tous les poids à chaque itération, on constate que l'algorithme ne
converge que pour des faibles valeurs de
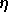 .
Au delà l'algorithme est très
instable. Donc deux autres approches sont proposées. Dans la première,
dite
aléatoire, à chaque itération un seul des
neurones, sélectionné aléatoirement, est mis à jour et les poids des
autres neurones ne sont pas modifiés. Dans la seconde approche, dite
asynchrone, la mise à jour des poids se fait successivement sur chaque
neurone pour chaque exemple. C'est à dire que pour chaque exemple de
la base d'apprentissage on calcule
.
Au delà l'algorithme est très
instable. Donc deux autres approches sont proposées. Dans la première,
dite
aléatoire, à chaque itération un seul des
neurones, sélectionné aléatoirement, est mis à jour et les poids des
autres neurones ne sont pas modifiés. Dans la seconde approche, dite
asynchrone, la mise à jour des poids se fait successivement sur chaque
neurone pour chaque exemple. C'est à dire que pour chaque exemple de
la base d'apprentissage on calcule 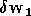 ,
puis la nouvelle valeur de
,
puis la nouvelle valeur de 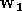 ,
puis
,
puis 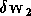 ,
puis la nouvelle valeur de
,
puis la nouvelle valeur de 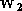 etc... L'itération
se termine lorsque tous les exemples ont été parcourus. Ces deux
approches permettent de converger plus rapidement qu'en appliquant
strictement l'algorithme de descente du gradient avec un
faible.
etc... L'itération
se termine lorsque tous les exemples ont été parcourus. Ces deux
approches permettent de converger plus rapidement qu'en appliquant
strictement l'algorithme de descente du gradient avec un
faible.
Le réseau Pi-Sigma a été testé avec de nombreux exemples de bases d'apprentissage dans [JOYD92], et les simulations montrent qu'il est capable de réaliser un grand nombre de fonctions complexes avec un nombre de neurones et de poids réduit par rapport au HPU ou au perceptron multicouches.
Le réseau Pi-Sigma permet d'approximer un grand nombre de fonctions, en utilisant des corrélations d'ordre élevé entre les entrées avec un nombre réduit de poids. Cependant ce réseau n'est pas un approximateur universel, c'est à dire que certaines fonctions ne pourront pas être approximées par le réseau, quel que soit le nombre de neurones choisis. Le réseau RPN (Ridge Polynomial Network) [SHIN92] est un autre réseau basé sur le Pi-Sigma, qui lui est approximateur universel.
Le principe d'un réseau RPN est de
calculer la somme des sorties de plusieurs réseaux Pi-Sigma. Chaque
réseau Pi-Sigma ne possède pas de
fonction d'activation (c'est à dire que
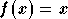 dans les formules précédentes) et la fonction d'activation est
placée après la somme. Dans la figure 2.22
chaque PSNi représente un réseau Pi-Sigma
d'ordre i avec une fonction d'activation linéaire.
dans les formules précédentes) et la fonction d'activation est
placée après la somme. Dans la figure 2.22
chaque PSNi représente un réseau Pi-Sigma
d'ordre i avec une fonction d'activation linéaire.
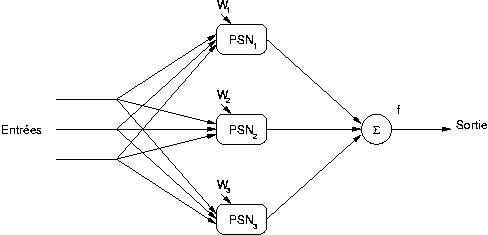
Un réseau RPN
d'ordre
est composé de
réseaux Pi-Sigma, d'ordres respectifs
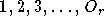 .
La sortie d'un réseau RPN est donnée par :
.
La sortie d'un réseau RPN est donnée par :
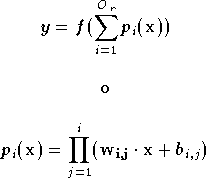
L'apprentissage d'un réseau RPN se fait de manière itérative. Tout d'abord seul le premier réseau Pi-Sigma, d'ordre 1, est placé dans le réseau. Un apprentissage est réalisé sur ce réseau. Ensuite les poids du premier réseau Pi-Sigma sont figés, et le second réseau, d'ordre 2, est intégré dans le réseau RPN. Un apprentissage est réalisé, puis ses poids sont figés, et ainsi de suite. L'apprentissage est stoppé lorsque la précision voulue est atteinte ou lorsque l'ordre du réseau RPN a atteint une certaine limite. L'algorithme d'apprentissage utilisé sur chaque réseau Pi-Sigma peut être l'un de ceux évoqués dans la section 4.4. Chaque ajout de réseau Pi-Sigma permet d'affiner l'approximation effectuée par le réseau RPN.
Le réseau RPN permet de réaliser de meilleures approximations qu'un réseau Pi-Sigma, tout en gardant un nombre de poids inférieur à celui d'un réseau HPU d'ordre équivalent. Quelques exemples de problèmes où le réseau RPN a les meilleures performances sont donnés dans [SHIN95].
Les réseaux d'ordre supérieur permettent d'approximer certaines fonctions dans de meilleures conditions (avec de meilleures performances, ou avec une complexité ou un temps d'apprentissage moins long) que les réseaux plus classiques, tels que les perceptrons et les GRBF. Les différentes architectures présentées ici ont chacune des avantages et des inconvénients aux niveaux des capacités d'approximation et de la complexité de calcul. Chacune est donc adaptée à des problèmes spécifiques. Malheureusement il n'existe pas de méthode pour déterminer par avance quelle architecture sera adaptée à un problème donné, et généralement il faut tester plusieurs architectures afin de choisir celle qui offre les meilleures performances.