Les réseaux GRBF forment une première famille de réseaux de neurones. On va tout d'abord voir comment est constitué un tel réseau, puis ensuite leur apprentissage.
Le réseau GRBF (Gaussian Radial Basis Functions,
base de fonctions radiales gaussiennes)[6]
est un
réseau à deux couches [POGG89].
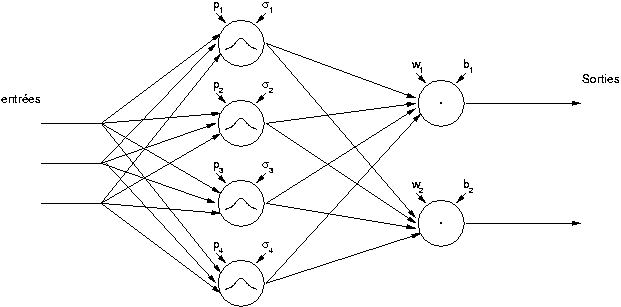
Les neurones de la première couche sont reliés aux entrées et ont chacun
deux paramètres : un vecteur prototype
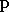 et un
coefficient d'étalement
et un
coefficient d'étalement  strictement positif. La fonction réalisée, de forme
gaussienne, est la
suivante :
strictement positif. La fonction réalisée, de forme
gaussienne, est la
suivante :
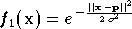
Le vecteur
prototype
définit un point dans
l'espace d'entrée. La sortie  du neurone est égale à 1 pour une entrée
du neurone est égale à 1 pour une entrée
 égale à ,
puis décroît vers 0 lorsque l'entrée s'éloigne de
.
La vitesse de décroissance est réglée par
:
plus le coefficient est petit et plus la fonction sera concentrée autour
du point
et proche de 0 ailleurs.
égale à ,
puis décroît vers 0 lorsque l'entrée s'éloigne de
.
La vitesse de décroissance est réglée par
:
plus le coefficient est petit et plus la fonction sera concentrée autour
du point
et proche de 0 ailleurs.
Les neurones de la seconde couche quand à eux calculent la sortie du réseau en effectuant une combinaison linéaire des sorties de ceux de la première couche, et un biais est ajouté au total. La fonction qu'ils réalisent est la suivante :
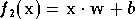
où
est un vecteur composé des sorties de tous les neurones de la première
couche, 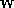 est un vecteur de poids et
est un vecteur de poids et 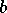 est le biais.
et
sont ajustés lors de l'apprentissage. Ainsi le réseau peut être
représenté par le schéma suivant :
est le biais.
et
sont ajustés lors de l'apprentissage. Ainsi le réseau peut être
représenté par le schéma suivant :
Et chaque sortie du réseau GRBF est donnée par la formule :
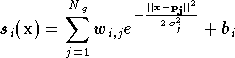
où 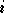 est le numéro de la sortie (c'est à dire le numéro du neurone de la
seconde couche dont on calcule la sortie),
est le numéro de la sortie (c'est à dire le numéro du neurone de la
seconde couche dont on calcule la sortie),
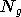 le
nombre de neurones de la première couche,
le
nombre de neurones de la première couche,
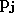 le vecteur prototype du neurone numéro
le vecteur prototype du neurone numéro  de la première couche,
de la première couche, 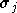 son coefficient d'étalement,
son coefficient d'étalement, 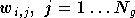 les
poids du neurone de sortie ,
et
les
poids du neurone de sortie ,
et 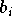 son biais.
son biais.
Il a été montré que le réseau GRBF est un approximateur universel [PARK91], c'est à dire que le réseau est capable d'approximer n'importe quelle fonction douce avec une précision donnée, pourvu que l'on fournisse un nombre suffisant de neurones, et que l'on utilise un algorithme d'apprentissage adéquat. Lors de l'apprentissage d'un réseau GRBF deux problèmes se posent : la constitution de la première couche (choix du nombre de neurones, choix des prototypes et des coefficients d'étalement), et la détermination des poids et biais de la seconde couche.
Le choix du nombre de neurones sur la première couche et de leurs
prototypes
correspondants dépend fortement de la répartition des entrées, c'est
à dire des vecteurs 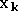 de la
base d'apprentissage. Pour établir ce choix, différentes méthodes
sont applicables. On peut répartir les prototypes uniformément ou
aléatoirement dans l'espace d'entrée, ou bien sélectionner
aléatoirement quelques vecteurs de la base d'apprentissage. Ces
méthodes sont très simples, mais ne donnent pas de bons résultats car
généralement la répartition obtenue n'est pas adaptée à la base. On
peut alors utiliser un algorithme de
clustering statistique, tel que les
k-means, afin de mieux les répartir dans l'espace d'entrée.
de la
base d'apprentissage. Pour établir ce choix, différentes méthodes
sont applicables. On peut répartir les prototypes uniformément ou
aléatoirement dans l'espace d'entrée, ou bien sélectionner
aléatoirement quelques vecteurs de la base d'apprentissage. Ces
méthodes sont très simples, mais ne donnent pas de bons résultats car
généralement la répartition obtenue n'est pas adaptée à la base. On
peut alors utiliser un algorithme de
clustering statistique, tel que les
k-means, afin de mieux les répartir dans l'espace d'entrée.
K-means est un algorithme itératif permettant de séparer une série de vecteurs dans différents groupes (les clusters) et chaque groupe est représenté par un prototype, placé en son centre. Dans l'exemple suivant la base est composée de 8000 vecteurs en deux dimensions, représentés ici sous la forme d'un nuage de points. 5 prototypes ont été déterminés par un algorithme k-means, indiqués dans la figure 2.10 par une croix.
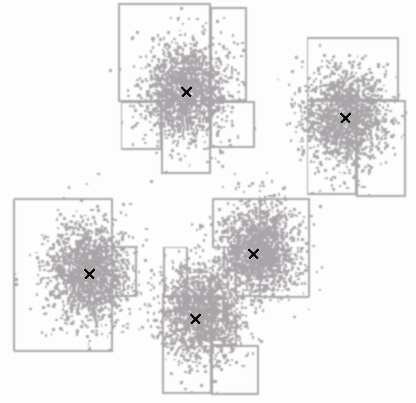
Le déroulement de l'algorithme k-means est le suivant : il faut tout d'abord choisir le nombre de prototypes désiré, empiriquement ou à l'aide de connaissances a priori sur la base d'apprentissage. Ensuite une série de prototypes initiaux est déterminée par l'une des méthodes précédentes (généralement un tirage aléatoire des exemples est utilisé). Puis chaque itération est réalisée en deux étapes. Chaque vecteur d'entrée de la base est classé dans un cluster en déterminant le prototype le plus proche, puis après avoir parcouru toute la base, la position de chaque prototype est recalculée, en prenant le barycentre de tous les exemples situés dans son cluster. L'algorithme s'arrête lorsque le système est stable, c'est à dire quand aucun vecteur ne change de cluster d'une itération à la suivante. La solution trouvée par l'algorithme k-means est une solution locale, c'est à dire qu'il ne garantit pas de trouver une solution optimale. Cependant dans la plupart des cas pratiques la solution trouvée est satisfaisante, lorsque le nombre de prototypes décidés est adapté à la base.
D'autres algorithmes ont été étudiés et peuvent être également utilisés. Le problème à résoudre s'apparente à la construction d'un dictionnaire pour une quantification vectorielle. Une étude comparative des différentes solutions possibles est réalisée dans [FOUC02]. Elle s'intéresse particulièrement au cas des images, mais la plupart des méthodes peuvent s'appliquer à d'autres cas.
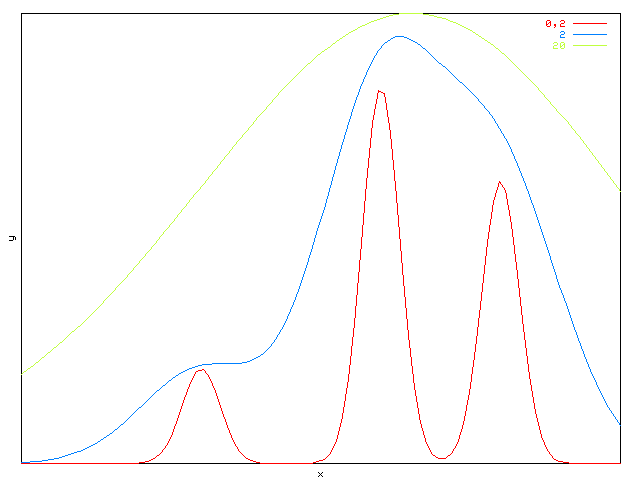
Le choix des coefficients d'étalement va influer sur la forme de la fonction réalisée. S'ils sont trop faibles, on verra apparaître des pics autour des points définis par les prototypes, et au contraire s'ils sont trop grands la fonction pourra difficilement prendre des valeurs différentes près de deux prototypes différents. Il est raisonnable de choisir une valeur qui soit de l'ordre de grandeur du carré de la distance entre deux prototypes voisins.
Une fois les prototypes placés, il reste a déterminer les
paramètres de la seconde couche, c'est-à-dire les
poids
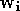 et biais
qui minimisent la fonction de performance du réseau. On peut calculer la
sortie de la première couche pour chaque exemple de la base
d'apprentissage :
et biais
qui minimisent la fonction de performance du réseau. On peut calculer la
sortie de la première couche pour chaque exemple de la base
d'apprentissage :
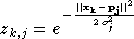
où 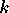 est le numéro de l'exemple et
celui de la composante de
est le numéro de l'exemple et
celui de la composante de 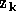 calculée, c'est-à-dire le numéro du neurone de la première couche
dont on calcule la sortie. Le critère à minimiser est
l'erreur quadratique moyenne du réseau sur la
base d'apprentissage et a donc pour expression :
calculée, c'est-à-dire le numéro du neurone de la première couche
dont on calcule la sortie. Le critère à minimiser est
l'erreur quadratique moyenne du réseau sur la
base d'apprentissage et a donc pour expression :
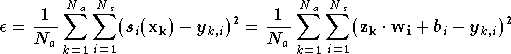
où 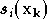 est la sortie du neurone
de la seconde couche ((2.12)),
est la sortie du neurone
de la seconde couche ((2.12)),
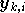 est la
est la 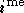 composante de
composante de 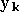 (c'est à dire la sortie voulue pour l'exemple
sur
le neurone
de la seconde couche) et
(c'est à dire la sortie voulue pour l'exemple
sur
le neurone
de la seconde couche) et 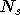 est le nombre de sorties. Un algorithme des moindres carrés peut être appliqué afin de
trouver les paramètres
et
qui minimisent ce critère.
est le nombre de sorties. Un algorithme des moindres carrés peut être appliqué afin de
trouver les paramètres
et
qui minimisent ce critère.
Cette méthode d'apprentissage qui consiste d'abord à sélectionner des prototypes puis ensuite à optimiser les poids de la seconde couche est simple à mettre en oeuvre. D'autres algorithmes, tels que EM (Expectation-Maximization) peuvent être appliqués aux GRBF afin de déterminer ces deux jeux paramètres en même temps, avec souvent une meilleure performance du réseau, mais aux pris d'un temps d'apprentissage plus long [BISH95]. Cependant toutes ces méthodes nécessitent de savoir par avance le nombre de prototypes à définir dans la première couche. D'autres méthodes ont donc été étudiées, de type incrémental, c'est à dire que des prototypes sont ajoutés dans la première couche au fur et à mesure des besoins de l'apprentissage.
Le principe d'une méthode incrémentale est de commencer avec un faible nombre de neurones sur la première couche (1 ou 2 par exemple) puis de commencer l'apprentissage, et ajouter au fur et à mesure des neurones sur la première couche jusqu'à ce que la fonction de performance du réseau soit en dessous d'un certain seuil, ou que le nombre de neurones ait atteint une valeur maximale. Généralement les réseaux ainsi obtenus possèdent moins de neurones et nécessitent donc moins de calcul lors de l'exploitation.
Plusieurs algorithmes ont été proposés dans la littérature. Dans [KURK95], les auteurs commencent avec un réseau ne comportant qu'un seul neurone sur la première couche. La détermination du prototype de ce neurone se fait de la manière suivante : chaque élément de la base est testé comme prototype, avec à chaque fois une détermination des poids correspondants dans la deuxième couche par une méthode des moindres carrés. C'est le prototype qui engendre l'erreur quadratique moyenne la plus faible qui est gardé. Ensuite cette erreur quadratique est comparée au seuil voulu. Si le seuil n'est pas atteint, un second neurone est ajouté par la même méthode, et ainsi de suite jusqu'à obtenir la performance voulue ou que le nombre de neurones a atteint un seuil maximal.
Avec cette méthode la première couche est figée, c'est à dire qu'une fois le prototype du nouveau neurone choisi il ne changera plus au cours du reste de l'apprentissage. Dans un autre algorithme proposé dans [FRIT94], les prototypes sont légèrement déplacés au cours de chaque itération, selon un algorithme de type "neural gas". Cet algorithme demande plus de calcul, mais permet d'affiner le modèle en prenant en compte l'influence des "anciens" neurones présents dans le réseau et ainsi de mieux répartir les prototypes.
Les réseaux GRBF approximent localement les fonctions. En effet les neurones de la première couche ne produisent de valeurs significatives en sortie que dans une certaine zone de l'espace d'entrée (c'est à dire que leur sortie est proche de 1 pour une entrée proche de leur prototype et proche de 0 ailleurs). La seconde couche permet d'associer une certaine sortie à chaque zone. Les réseaux GRBF sont donc particulièrement adaptés lorsque les vecteurs des entrées sont regroupés par zones, tel que dans l'exemple indiqué pour l'algorithme des k-means (figure 2.10). Dans cette situation les GRBF ont généralement de meilleures performances que les autres solutions neuronales, ou des performances équivalentes pour une complexité moindre. Par contre lorsque les vecteurs d'entrée sont répartis plus uniformément, ou lorsque le nombre de dimensions de l'espace d'entrée est important, le nombre de prototypes nécessaires augmente rapidement et les réseaux GRBF perdent leur intérêt. Enfin un autre avantage des réseaux GRBF est leur rapidité d'apprentissage, plus grande que pour le perceptron, que nous allons présenter maintenant.
[6] dans la littérature on peut trouver également le sigle RBF (Radial Basis Functions, base de fonction radiales) pour décrire ces réseaux, et le fait que les fonctions radiales soient gaussiennes est souvent implicite. Dans ce mémoire nous utiliserons le sigle GRBF.